How to deploy the DeepSeek-R1 distilled model on LattePanda Mu?
Introduction
How to effectively enhance reasoning ability during the training process of large language models has been the focus of researchers.
Traditional reasoning models typically rely on vast amounts of data and computational resources, but by adjusting computational strategies and training methods, the performance of many models has been significantly improved. This approach ultimately led to the groundbreaking advancement of DeepSeek - the DeepSeek-R1 model.
DeepSeek-R1 is not merely a simple language model, it has achieved impressive results through innovative training methods, particularly the application of reinforcement learning (RL) to reasoning training in basic language models. Unlike traditional supervised learning methods, DeepSeek-R1's training is entirely independent of manual annotations and instead, through the reward mechanism of reinforcement learning, allows the model to enhance its reasoning ability autonomously. Throughout this process, the model gradually learns how to handle complex reasoning tasks such as mathematical problems and programming logic through continuous self-feedback.
The key to this technological innovation lies in DeepSeek-R1's adoption of a specific training process, which building upon the basic model, gradually enhances the model's reasoning ability through two rounds of reinforcement learning and fine-tuning. In the initial "cold-start" phase, DeepSeek-R1 undergoes fine-tuning with a small set of carefully designed samples to improve the model's reasoning clarity and readability. Next, the model enters the reinforcement learning phase, optimizing by rejecting low-quality outputs and based on feedback rewards, ultimately achieving a dual enhancement in reasoning ability and answer clarity.
It is worth noting that DeepSeek-R1's training method does not solely rely on traditional datasets, but meticulously constructs a data mix suitable for reasoning tasks to better improve the model's performance in specific domains. Through this approach, DeepSeek-R1 efficiently learns how to deduce reasoning and solve complex problems without requiring extensive human intervention.
How to perform on-premise deployment?
How to bring this strong reasoning ability into practical applications, especially running on devices with relatively limited hardware resources?
Traditional boards like Jetson Orin and Nano, while powerful in performance, are either expensive or bulky in size. Coupled with constraints in specific system environments, they may encounter a series of difficulties in real-world scenarios. However, now you have a better option - LattePanda Mu.
LattePanda Mu is a high-performance micro x86 computing module powered by an Intel N100 quad-core processor with 8GB of LPDDR5 RAM and 64GB of storage. With these robust hardware configurations, LattePanda Mu can deliver smooth computing and reasoning capabilities, ideal for running complex deep learning tasks. In addition, LattePanda Mu offers a variety of expansion interfaces, including 3 HDMI/DisplayPort ports, 8 USB 2.0 ports, up to 4 USB 3.2 ports, and up to 9 PCIe 3.0 lanes. These ports make LattePanda Mu highly flexible in connecting external devices and customizing hardware.
Most specifically, LattePanda Mu also offers open source carrier board design files, allowing users to customize or design a specific carrier board according to their needs. This makes LattePanda Mu not just an ordinary computing module, but a development platform that can be flexibly expanded and customized based on project requirements.
To smoothly run the DeepSeek-R1 model on LattePanda Mu, the first step is to select a suitable framework to load and execute the large language model. According to the official DeepSeek documentation, local deployment can be done using VLLM and SGLang. However, in most cases, these two calling methods are not only complex but also take up a large amount of space. Additionally, MU N100 currently cannot utilize OpenVINO™ acceleration in the Linux environment. Therefore, today we recommend another efficient and quick method - Ollama.
With just two simple commands, you can easily run the R1 model with Ollama.
Install Ollama

Download and install Ollama from the official website: https://ollama.com/download
If you are using Ubuntu system, you can directly install it with the command curl -fsSL https://ollama.com/install.sh.
You can also install it on other systems.
Download and run Deepseek-R1
We choose models with different parameter sizes based on performance and actual needs.

For those without professional-grade graphics cards, we recommend using models under 14B.


The machine requirements for 32B, 70B, and 671B are as follows:
DeepSeek-R1-Distill-Qwen-32B
- VRAM requirements: Approximately 14.9GB
- Recommended GPU configuration: NVIDIA RTX 4090 24GB
- RAM: minimum of 32GB recommended
DeepSeek-R1-Distill-Llama-70B
- VRAM Requirements: Approximately 32.7GB
- Recommended GPU configuration: NVIDIA RTX 4090 24GB × 2
- RAM: 48GB or higher recommended
DeepSeek-R1 671B (full model)
- VRAM requirement: Approximately 1,342GB (using FP16 precision)
- Recommended GPU configuration: multi-GPU setup, e.g. NVIDIA A100 80GB × 16
- RAM: 512GB or higher
- Storage: 500GB or higher high-speed SSD
Note that for the 671B model:
- Typically requires enterprise-grade or data center-grade hardware to manage its massive memory and computational loads.
- Quantization techniques can significantly reduce VRAM requirements. For example, after 4-bit quantization, the model size can be reduced to approximately 404GB.
- Dynamic quantization techniques can further reduce hardware requirements by quantizing most parameters to 1.5-2.5 bits, reducing the model size to between 212GB-131GB.
- For local deployments, it may be necessary to consider using multiple high-performance workstations or servers, such as multiple Mac Studios (M2 Ultra, 192GB RAM) to meet memory requirements.
- When running the full 671B model, power consumption (potentially up to 10kW) and heat dissipation considerations should also be taken into account.
In summary, 32B and 70B models can run on high-end consumer-grade hardware, while the 671B model requires enterprise-grade or data center-grade hardware configuration. When choosing the appropriate hardware configuration, specific use cases, performance requirements, and budget limitations should also be considered.
Reference for the running speed of LattePanda Mu
For different specifications of Mu and R1 models, the running speed reference in Ollama is as follows (tokens/s):

Ollama's official provides a tool to calculate the speed of reasoning, just type /set verbose in the chat window to make it automatically output the running speed after each reply.

The output results are as shown below.

Configure browser access
In addition to running Ollama in the command line, we can use a browser extension called Page Assist, which allows us to run our local models on the browser page.

You can install the extension directly by visiting the Chrome Web Store link https://chromewebstore.google.com/detail/page-assist-local-ai-model-web/jfgfiigpkhlkbnfnbobbkinehhfdhndo?pli=1,
or follow the installation steps as described on Page Assist's GitHub link
https://github.com/n4ze3m/page-assist.
Once the extension is installed, it is able to set up Ollama's models.
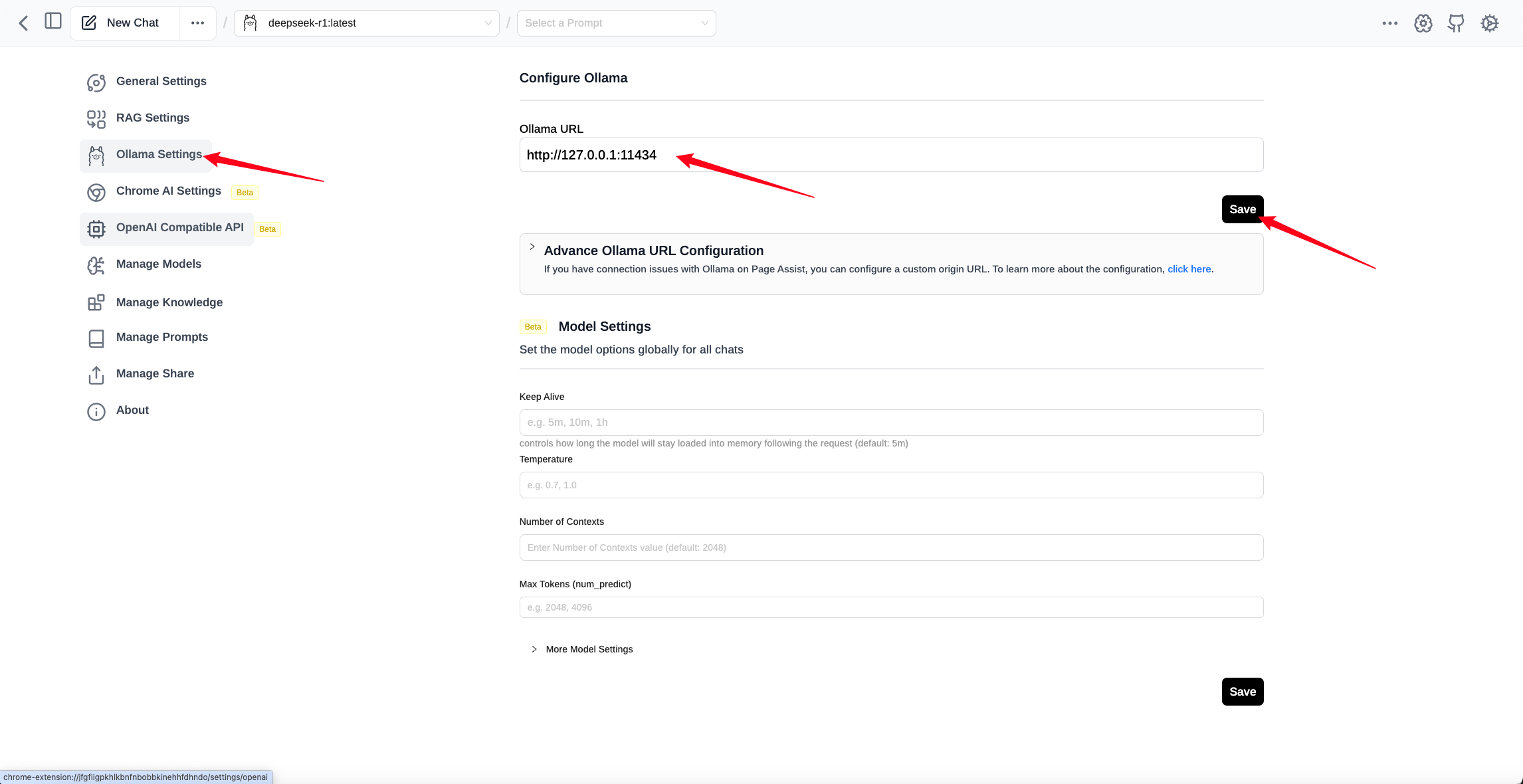
After setting the appropriate address, you can save it, and then you can use the corresponding model for question answering.

If you have multiple models, you can manage and add them to the model management section.
To enhance the use of models, you can also add your own knowledge base. Before using the knowledge base, you need to configure the RAG settings.
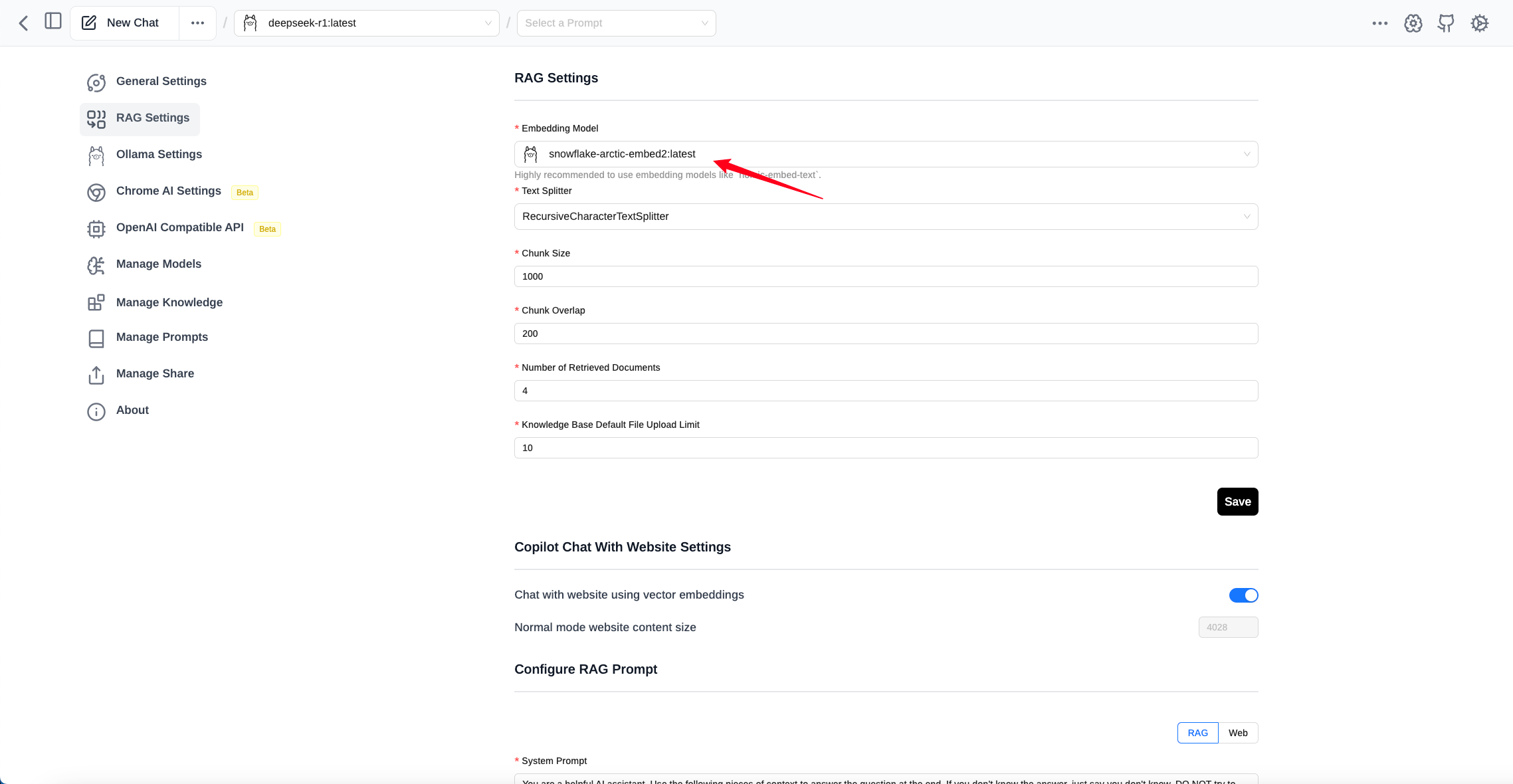
I have chosen the embedded model snowflake-arctic-embed2 at https://ollama.com/library/snowflake-arctic-embed2, but you can also choose recommended models. If not available, you can add them to model management.
Once completed, you can add knowledge to the knowledge base through the knowledge management.


You can then open the interface and select a model for conversation.
Page Assist also offers additional features, such as knowledge management and prompt word management. You can explore these features on your own. The key point is that now the usage is more intuitive!
Application scenarios
The DeepSeek R1 model has demonstrated its powerful adaptability and efficient reasoning capabilities across various domain, with one impressive application scenario being the generation of SQL queries from natural language commands.
Picture this: traditionally, crafting complex database query statements would require developers to possess deep SQL knowledge and experience. However, what sets the DeepSeek model apart is its ability to comprehend and parse natural language inputs from users, automatically generating precise SQL queries. This not only significantly reduces the barrier to entry but also enables non-technical users to interact efficiently with databases through concise language commands. (Especially those in data-sensitive departments.)


Moreover, DeepSeek also possesses a powerful contextual understanding capability, allowing it to generate personalized queries based on different business contexts and needs. Whether it involves relational database table operations or complex cross-table queries, DeepSeek can adeptly handle them, truly embodying the ideal of a "seamless human-computer interface."
In Summary
With technology advancing continuously, single-board computers and small computing platforms like LattePanda Mu offer more possibilities for edge computing, low-power devices, and customized scenarios. The flexibility and powerful reasoning capabilities of the DeepSeek model inject tremendous potential into these platforms. Whether in database query generation, text comprehension, or other intelligent application areas, DeepSeek has demonstrated significant value.
In the future, as platforms like LattePanda Mu and DeepSeek continue to be optimized and evolve, we can anticipate that more developers and researchers will be able to leverage the advantages of deep learning and large language models in various hardware environments. This will drive the implementation of more intelligent and efficient applications.
